Lonny schrieb:Du hast aber nicht einfach die Differenz zwischen Herdans und Guirauds gebildet und auf die eine raufaddiert oder abgezogen? :D
Lonny schrieb:Du hast aber nicht einfach die Differenz zwischen Herdans und Guirauds gebildet und auf die eine raufaddiert oder abgezogen? :D
Nein, habe ich nicht. Wie gesagt, ich hatte meine Formel gebildet, bevor ich von den anderen wußte. Sie ist allerdings auch recht simpel.
Allerdings habe ich irgendwann mal mit Guirauds und Herdans schlechtem Ergebnis herumgespielt. Bildet man den Mittelwert der mit Guirauds und Herdans Formel ermittelten Vokabelzahl pro Textlänge und Wortschatz, ist das so erzielte Ergebnis sogar noch etwas besser als das mit meiner Formel errrechnete. Und zwar sowohl in der Form "(Guiraud + Herdan) /2" als auch in der "sqrt (Guiraud * Herdan)". Das sieht dann so aus (alle Grafiken sind nochmal größer zu sehen, wenn sie in nem eigenen Fenster / Tab geöffnet werden):
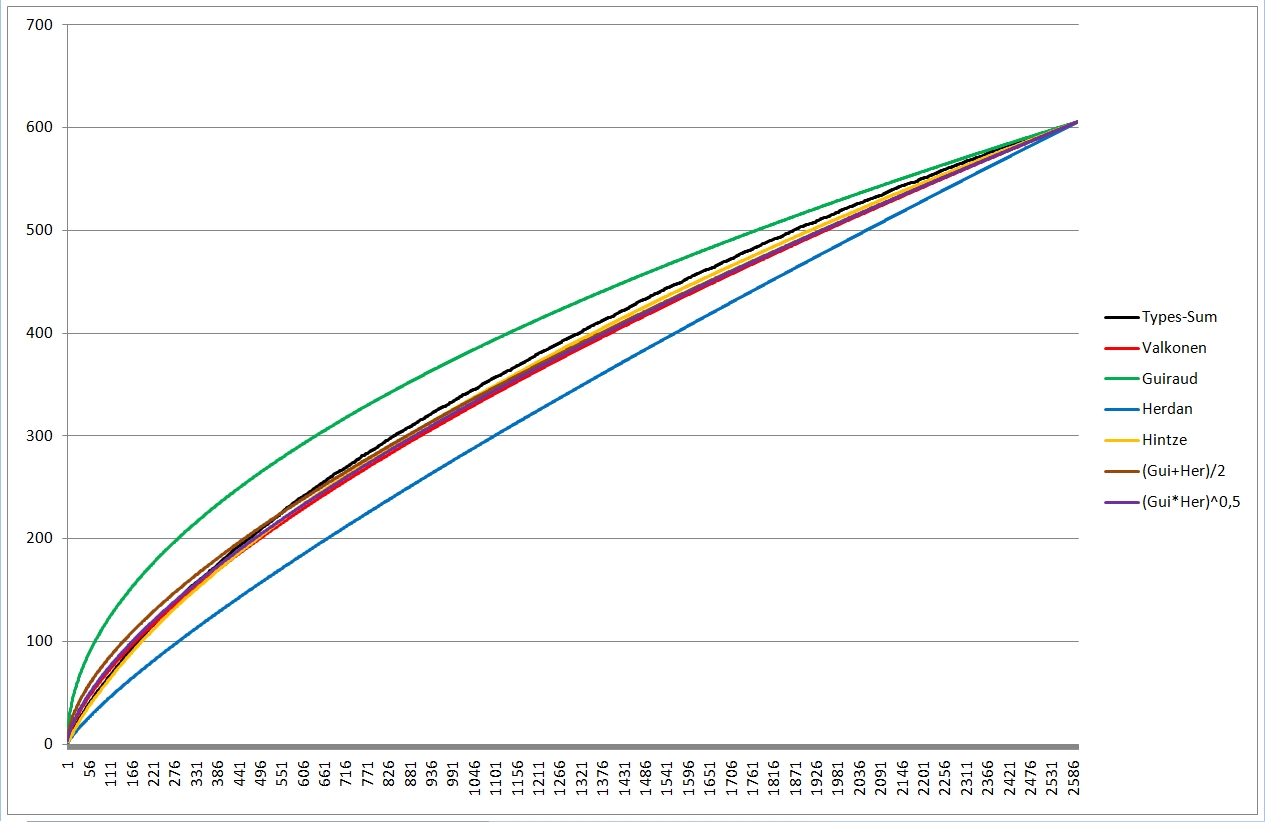
Is wirklich schon arg eng beieinander, kann man kaum noch auseinanderhalten.
Allerdings funktioniert das nur mit einer umständlichen Umrechnung; beim Abgleich zweier unterschiedlich langer Texte kann man nicht einfach die Wortschatzwerte der Formeln jener beiden zusammenrechnen und den Mittelwert bilden. Insofern bleibt meiner bei fast gleich genauen Ergebnissen doch weit einfacher händelbar.
Lonny schrieb:Vielleicht solltest du deine Formel mal irgendwo publizieren und anderen Menschen und auch der Nachwelt zur Verfügung stellen!
Ich werd sie hier später noch einstellen, den Ehrgeiz des Publizierens hab ich nicht (mehr).
 mojorisin schrieb:Hast du den Vergleich zwischen deiner und den anderen Modellen auch noch mit anderen Texten durchgeführt?
mojorisin schrieb:Hast du den Vergleich zwischen deiner und den anderen Modellen auch noch mit anderen Texten durchgeführt?
Ja, in Sachen NT-Texte. Ich stell es mal vor:
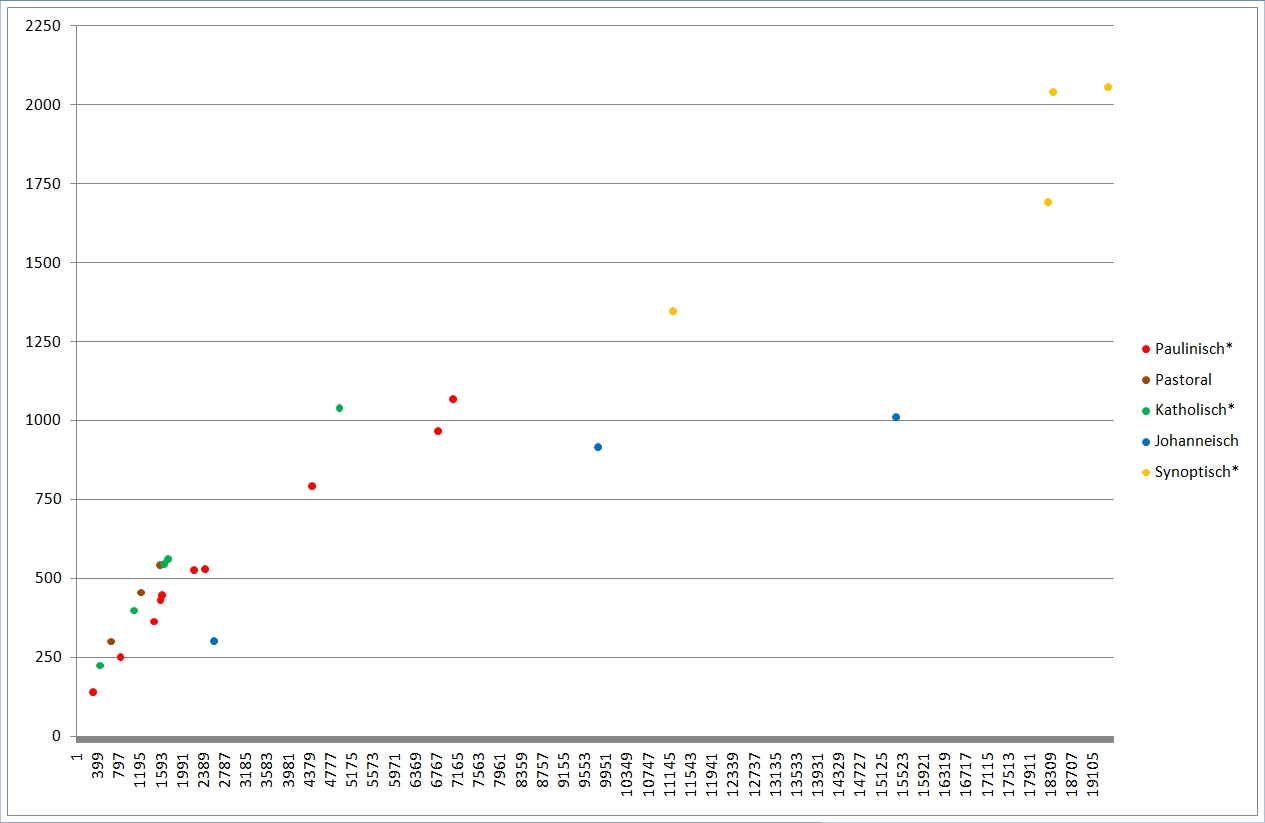
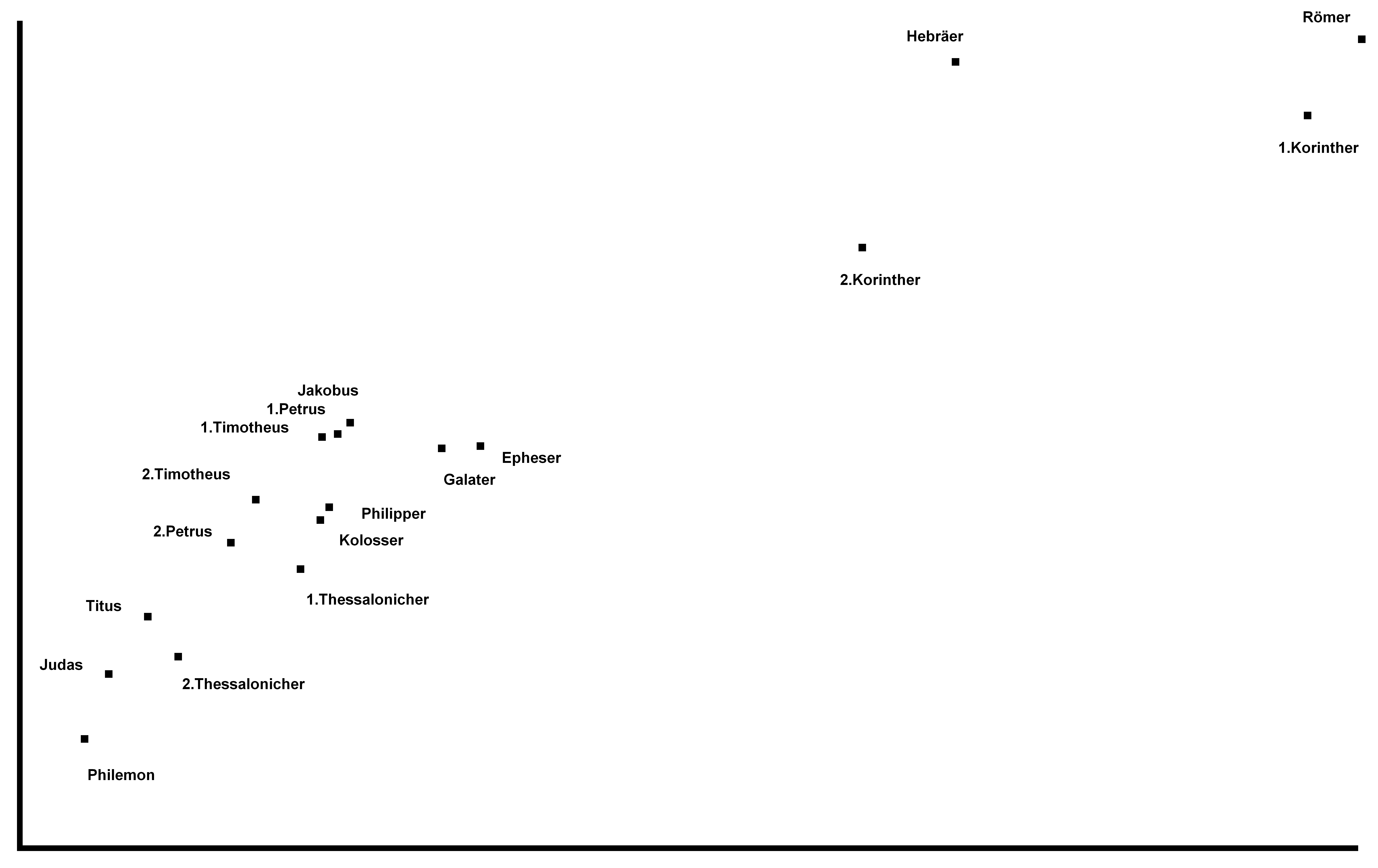
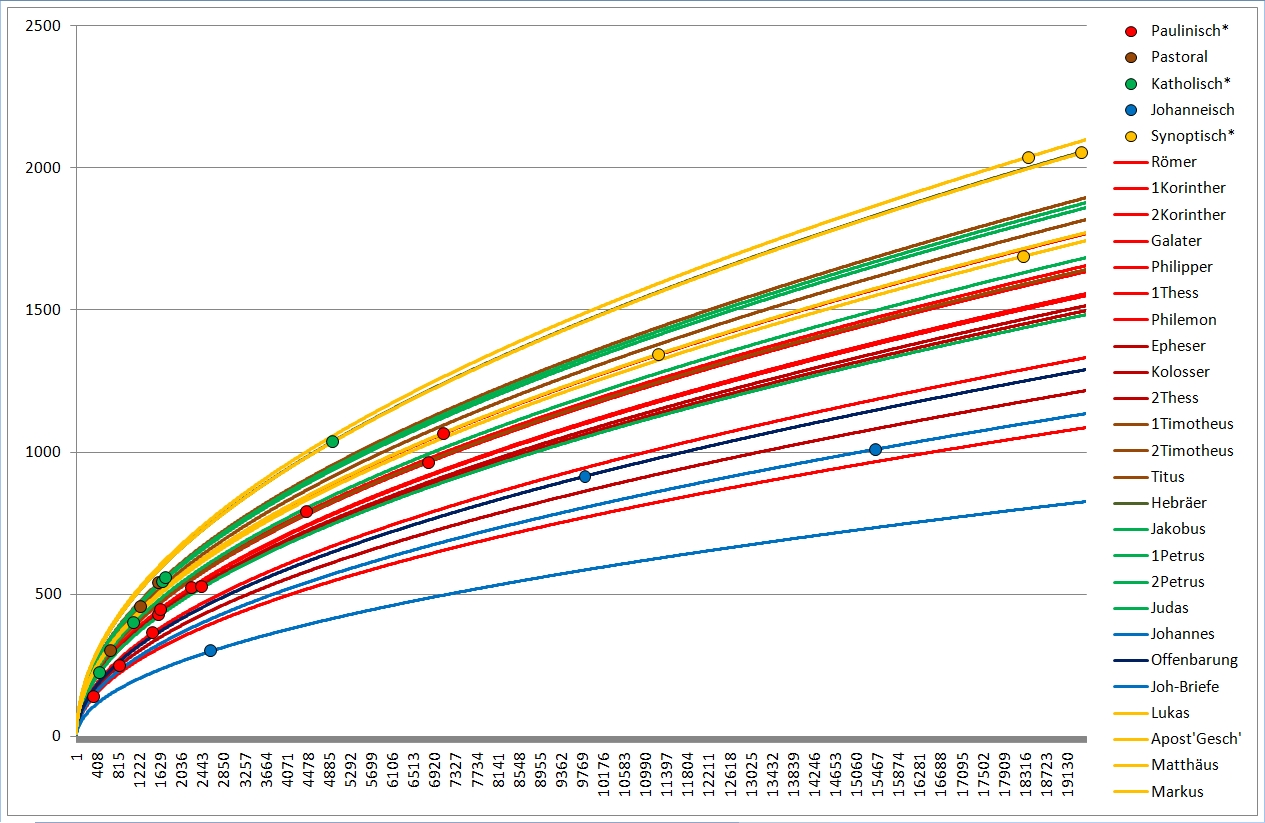
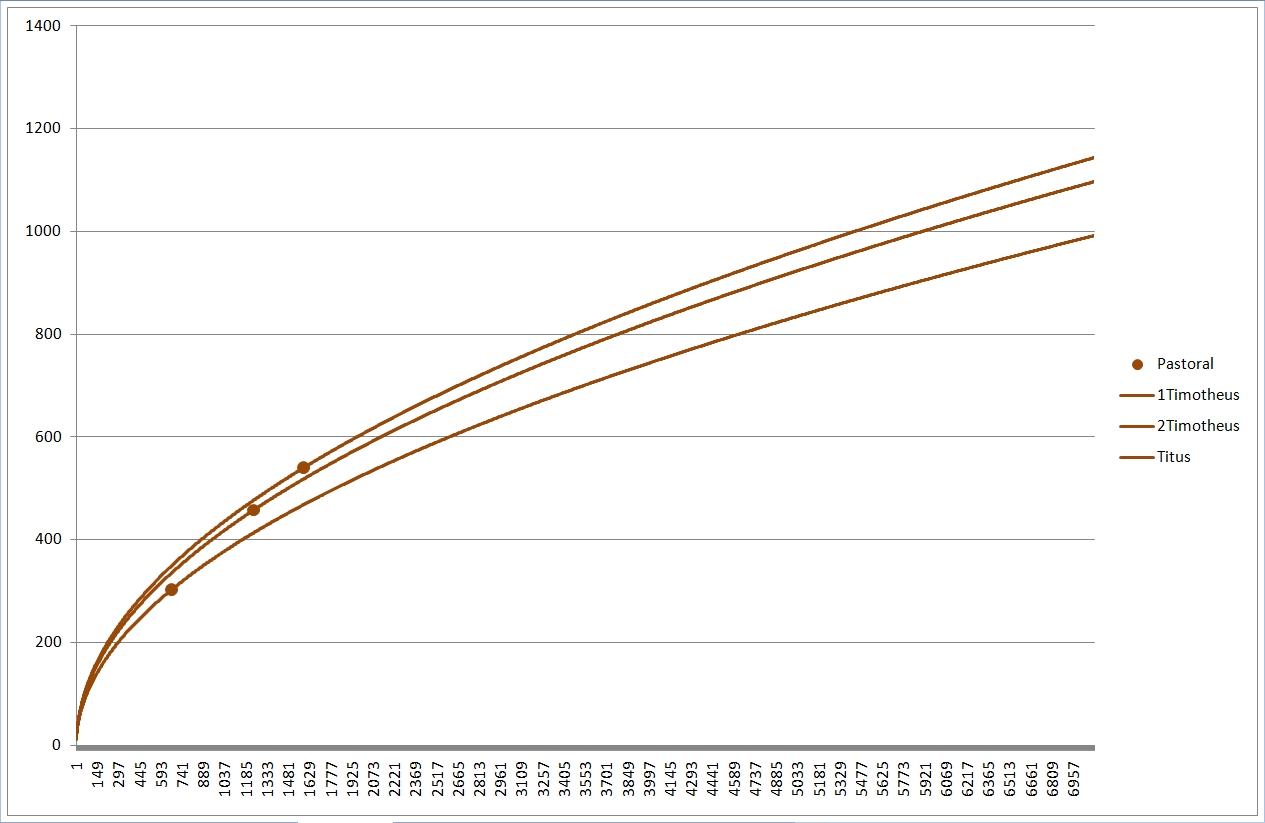
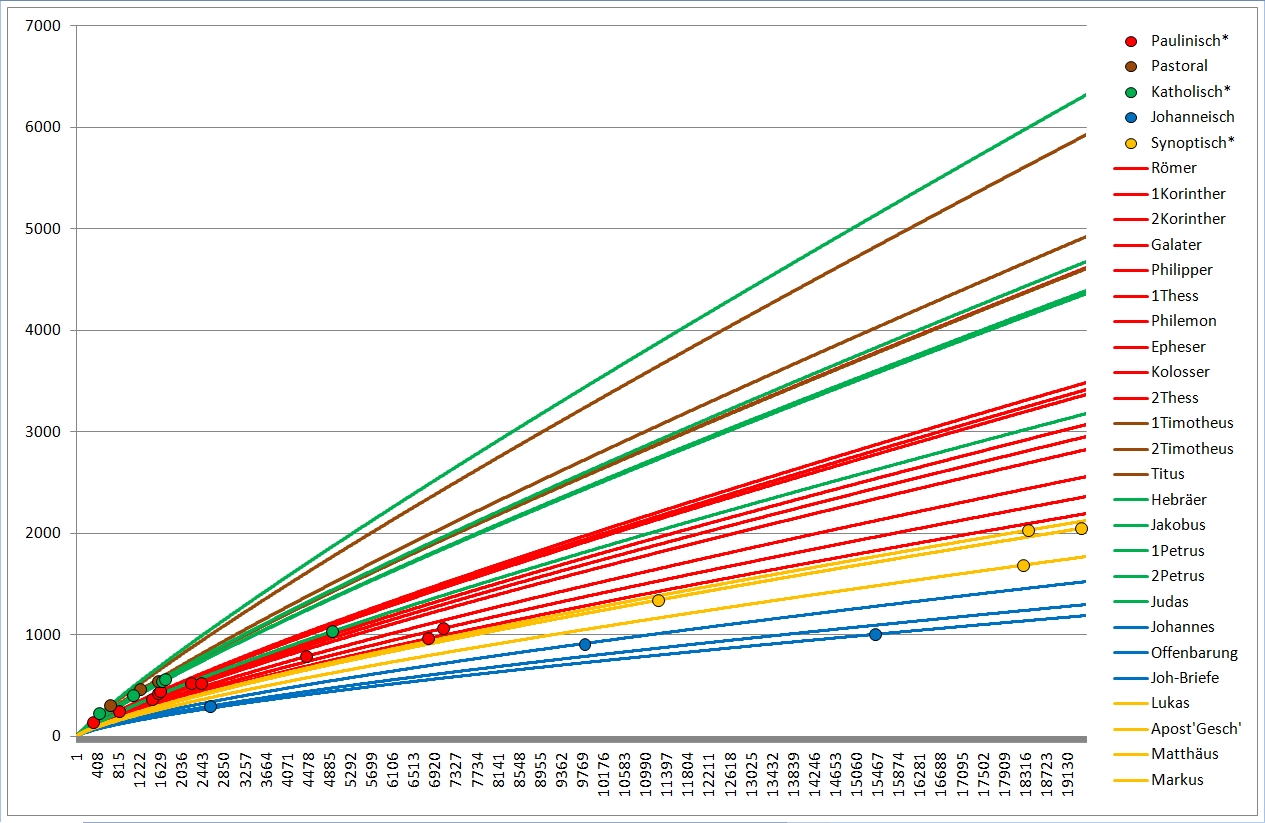
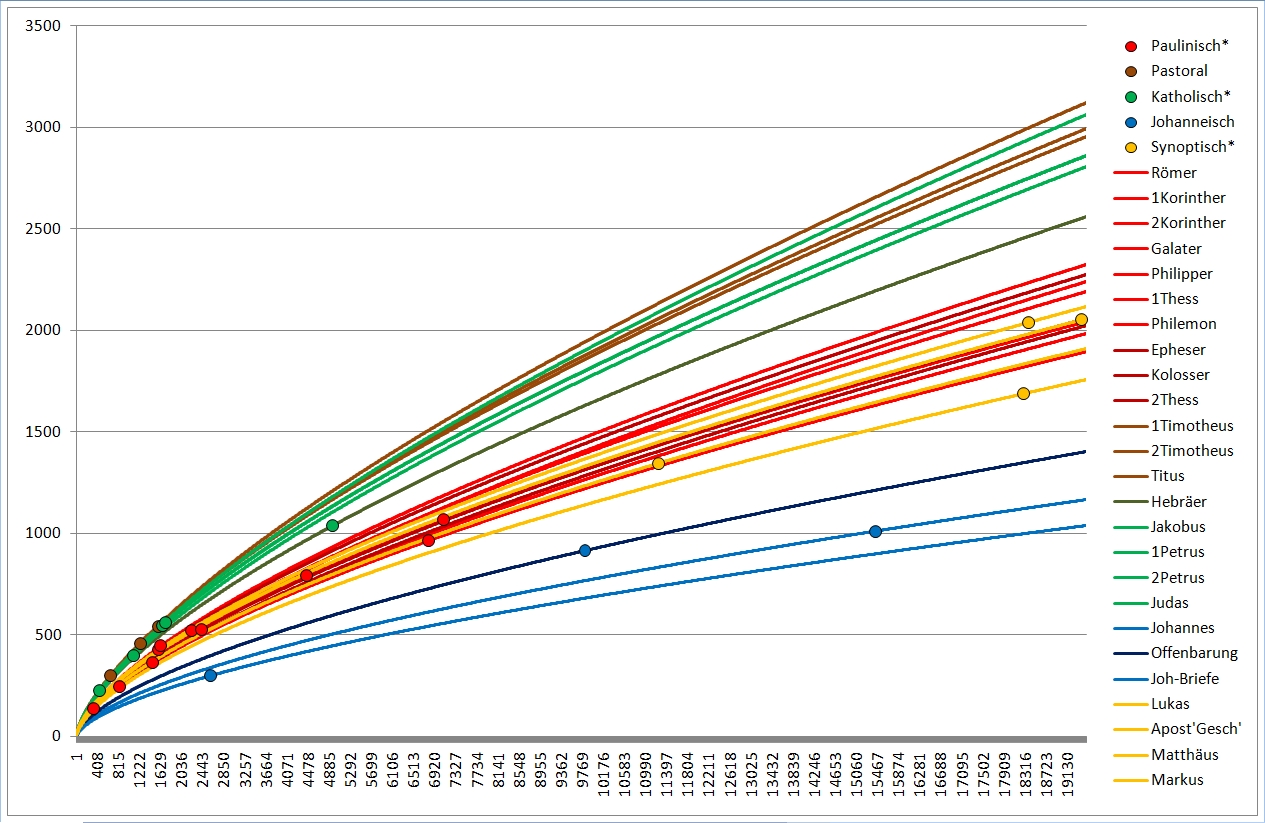
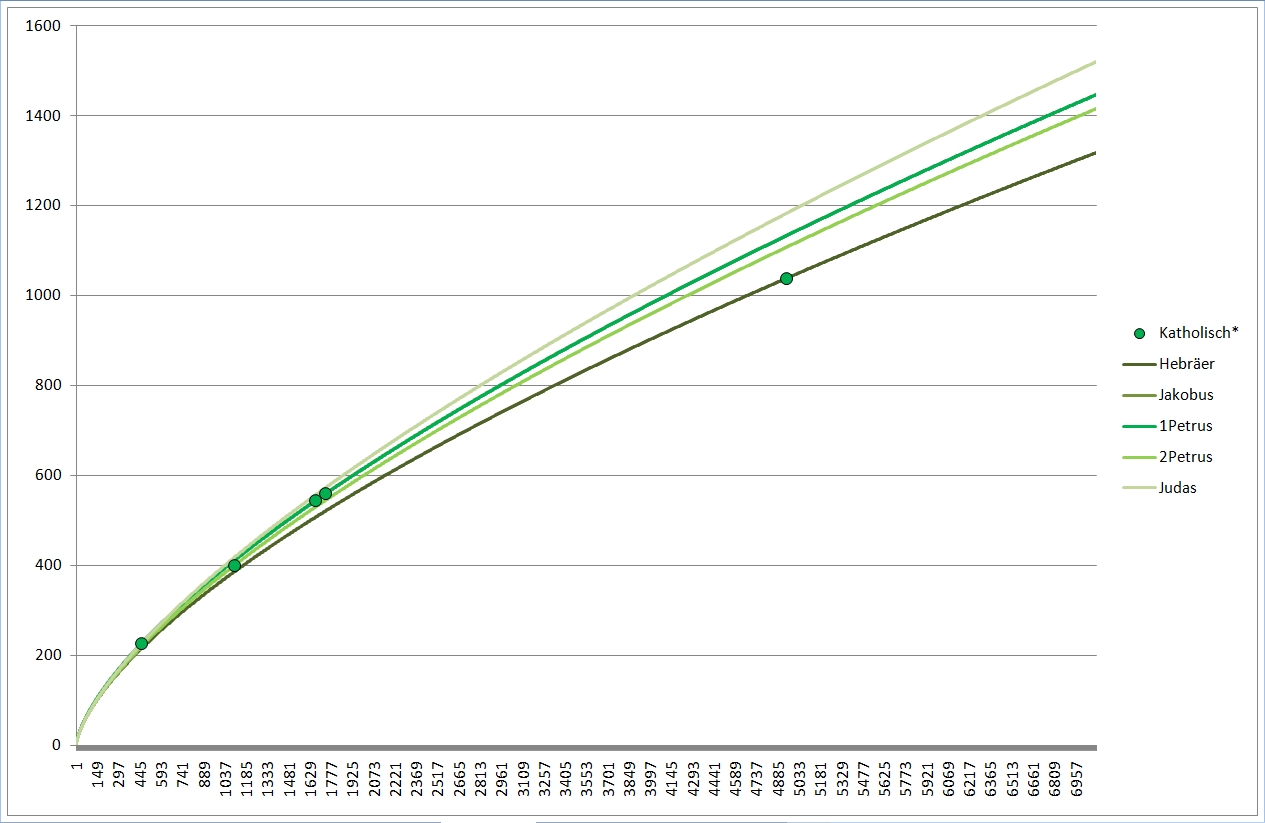
Das sind nochmals die einzelnen NT-Schriften. Nach rechts werden die Texte länger, nach oben vokabelreicher. Rot sind hier die meisten Paulusbriefe, die echten wie drei der von Späteren verfaßten, braun sind die drei nicht von Paulus verfaßten Pastoralbriefe, grün die übrigen Briefe, die wegen des allgemeinen Adressaten (Paulus schreibt an konkrete Gemeinden oder Personen) "katholische Briefe" genannt werden (katholisch heißt "allgemein"). Ganz ohne nähere Berechnung kann man erkennen, daß die rot markierten Briefe einen recht gleich hohen Wortschatz haben müssen, sowie daß die Pastoral- und katholischen Briefe ebenfalls einen vergleichbaren Wortschatz aufweisen, höher als der der Paulinen.
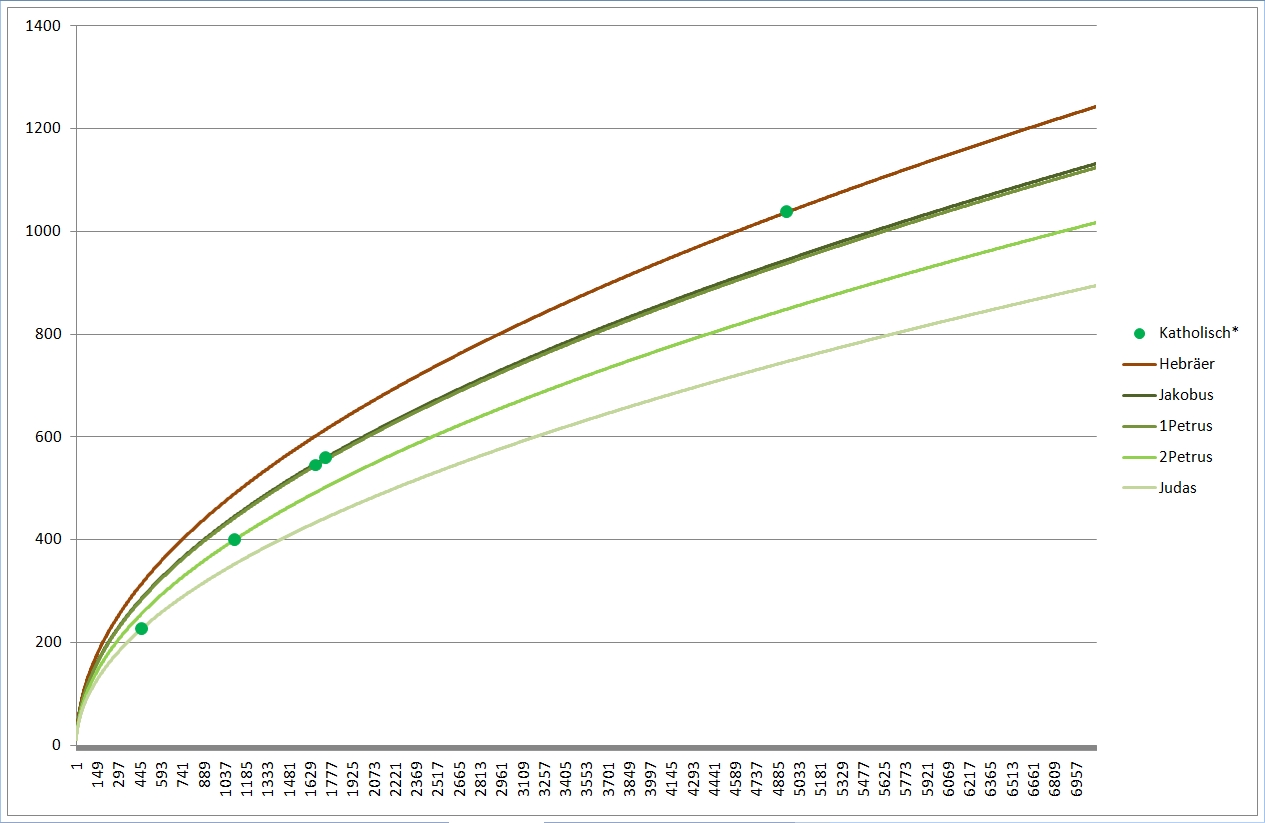
Blau sind die johanneischen Schriften, also die drei Johannesbriefe (hier als ein Text zusammengefaßt, der linke blaue Punkt), das Johannesevangelium (Punkt rechts) und die Offenbarung des Johannes, die Apokalypse (Punkt Mitte). Gelb sind die sog. synoptischen Evangelien sowie die Apostelgeschichte, von unten nach oben bzw. von links nach rechts Markus, Matthäus, Lukas (Apostelgeschichte), Lukas (Evangelium). Auch hier sieht man, daß die blauen und die gelben Punkte je für sich leidlich eng beieinander liegen in Sachen Wortschatz. Das Matthäusevangelium scheint den niedrigsten Wortschatz unter den Synoptikern zu haben, auch inhaltlich wirkt das Evangelium als das "Hebräischste", am stärksten am jüdischen Glaubenshintergrund interessierte. Der Verfasser mag ein Jude gewesen sein, für den Griechisch (alle NT-Schriften sind griechisch verfaßt) nicht die Muttersprache war, sodaß sein Wortschatz entsprechend eingeschränkt war. Für die johanneischen Schriften gilt dies deutlich erkennbar. Allerdings ist ebenfalls deutlich erkennbar, daß der Verfasser des Johannesevangeliums und der der Apokalypse nicht die selbe Person sein können, zu stark weicht der Wortschatz ab.
So weit lassen sich die Wortschatzeinstufungen bereits rein visuell erkennen.
Nun habe ich mal für jede NT-Schrift mit den verschiedenen Formeln den jeweiligen Wortschatzwert berechnet und anschließend wie bei Hänsel und Gretel damit ausgerechnet, wie viel Vokabeln eine bestimmte NT-Schrift haben müßte, wenn sie länger oder kürzer gewesen wäre. Daraus ergaben sich wieder diese Bogenlinien, und sinnigerweise sollten Bogenlinien von Texten ungefähr gleichen Wortschatzes auch ungefähr gleich nahe beieinanderliegen.
Leider konnte ich dies nicht für Hintze durchrechnen, denn für dessen Formel werden auch die Hapaxlegomena benötigt. Die weiß ich natürlich nicht für den Fall, daß der Römerbrief doppelt oder fünf mal so lang geworden wäre. Könnt ich mit Hintzes Formel zwar extrapolieren - aber nur, wenn ich dann schon weiß, wie viele verschiedene Vokabeln jener längere Römerbrief hätte. Einen der beiden Werte muß ich also vorher schon wissen, um den je anderen berechnen zu können. Daher muß Hintze bei diesem Abgleich außen vor bleiben.
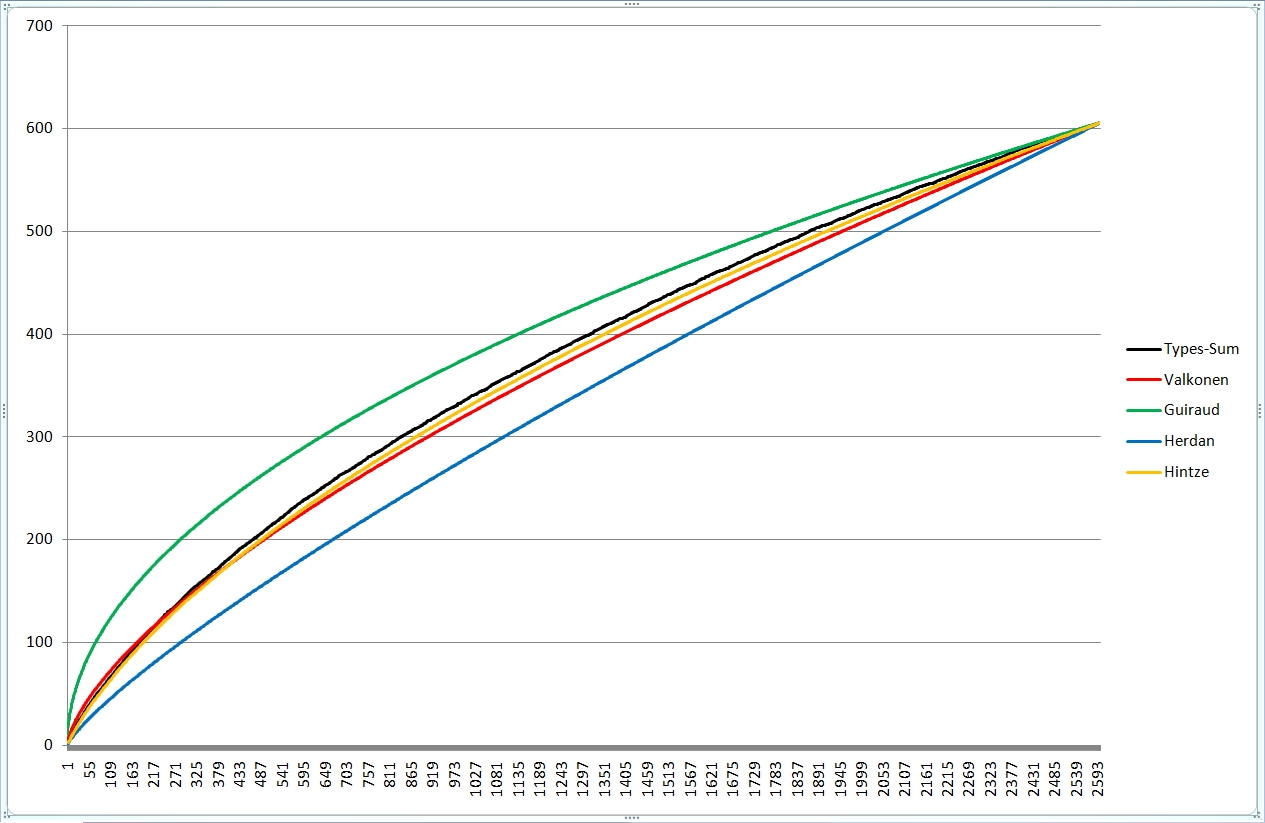
So, hier dann die Zusammenschauen:
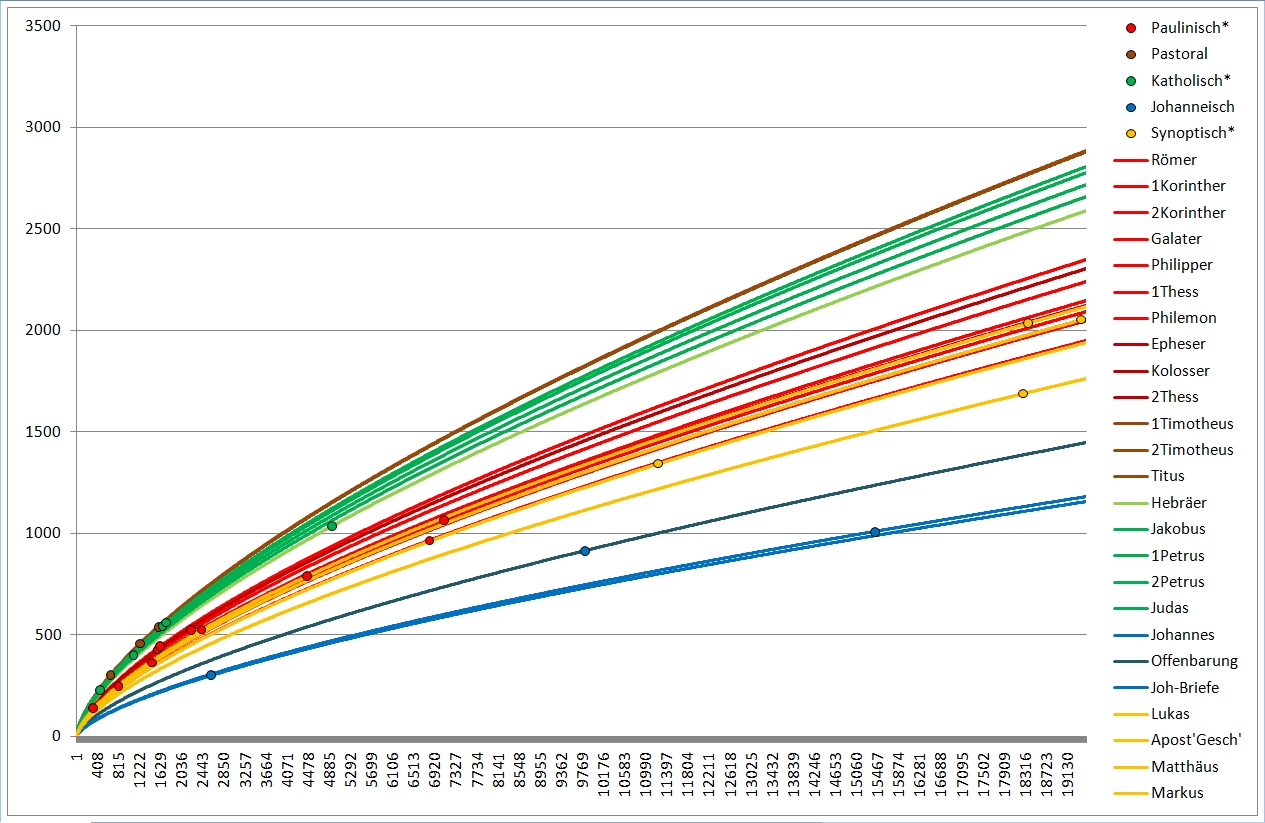
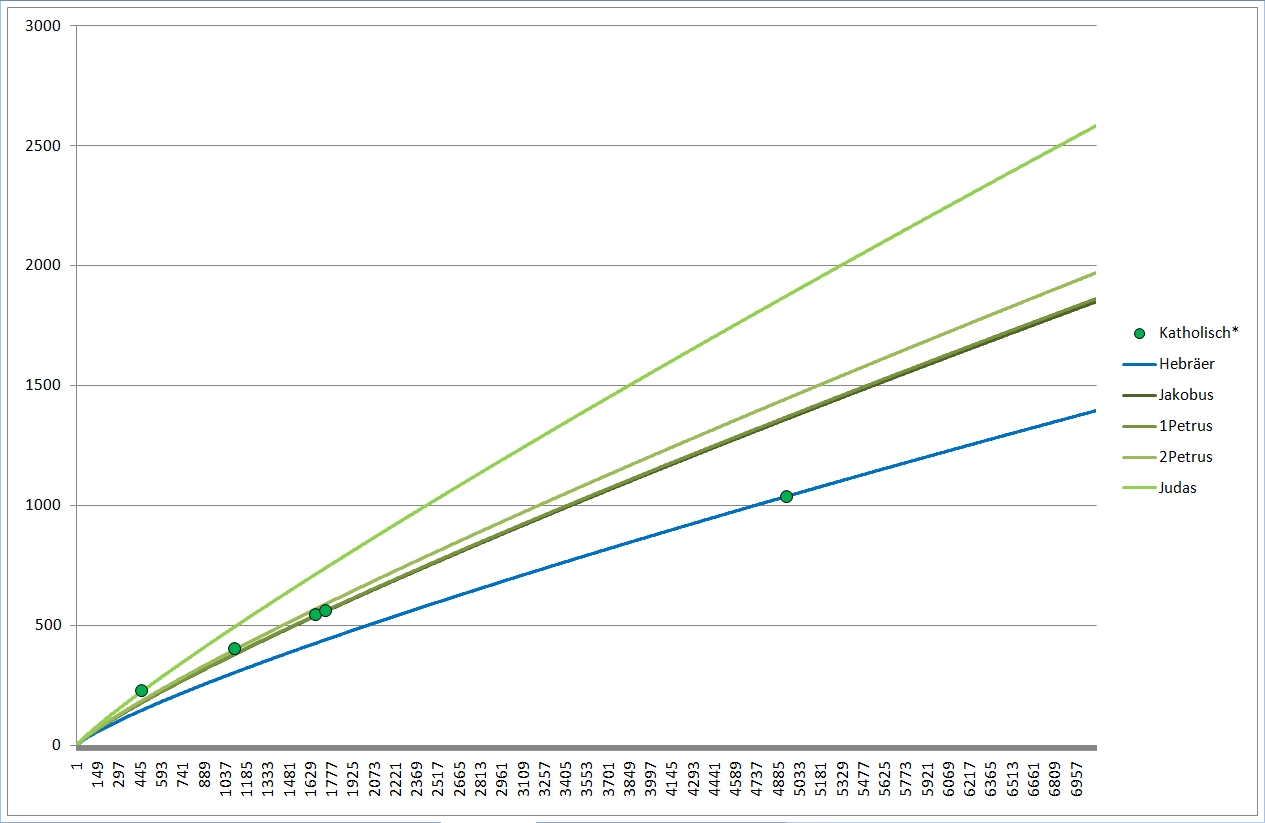
Deutlich erkennbar liegen bei Extrapolation mit meiner Formel die Wortschätze der (braun) Pastoralbriefe und der (grün) katholischen Briefe dicht beieinander, ebenso die Paulusbriefe (ohne Pastoral). Die beiden (gelb) Lukaswerke (Apostelgeschichte und Evangelium) liegen untereinander näher als mit Markus und vor allem Matthäus. Lukas gilt auch sonst als einer der gebildetsten bzw. des Griechischen Mächtigsten, was sich hier bestätigt. Er liegt ziemlich in der Mitte der roten, der paulinischen Linien; auch Paulus hatte einen hohen Bildungsstand. Beim Corpus Johanneum (blau) liegen Evangelium und Briefe eng beieinander, die Offenbarung hingegen deutlich davon abgesetzt.
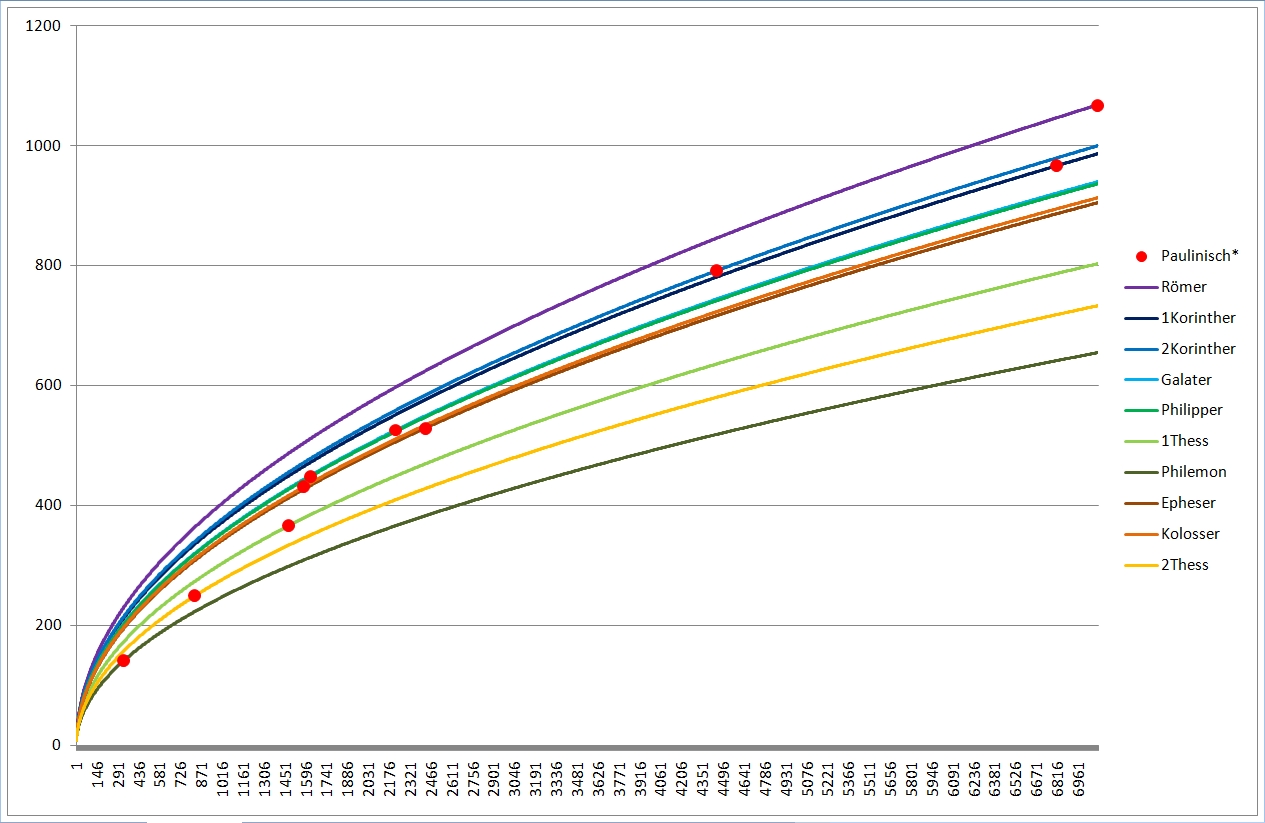
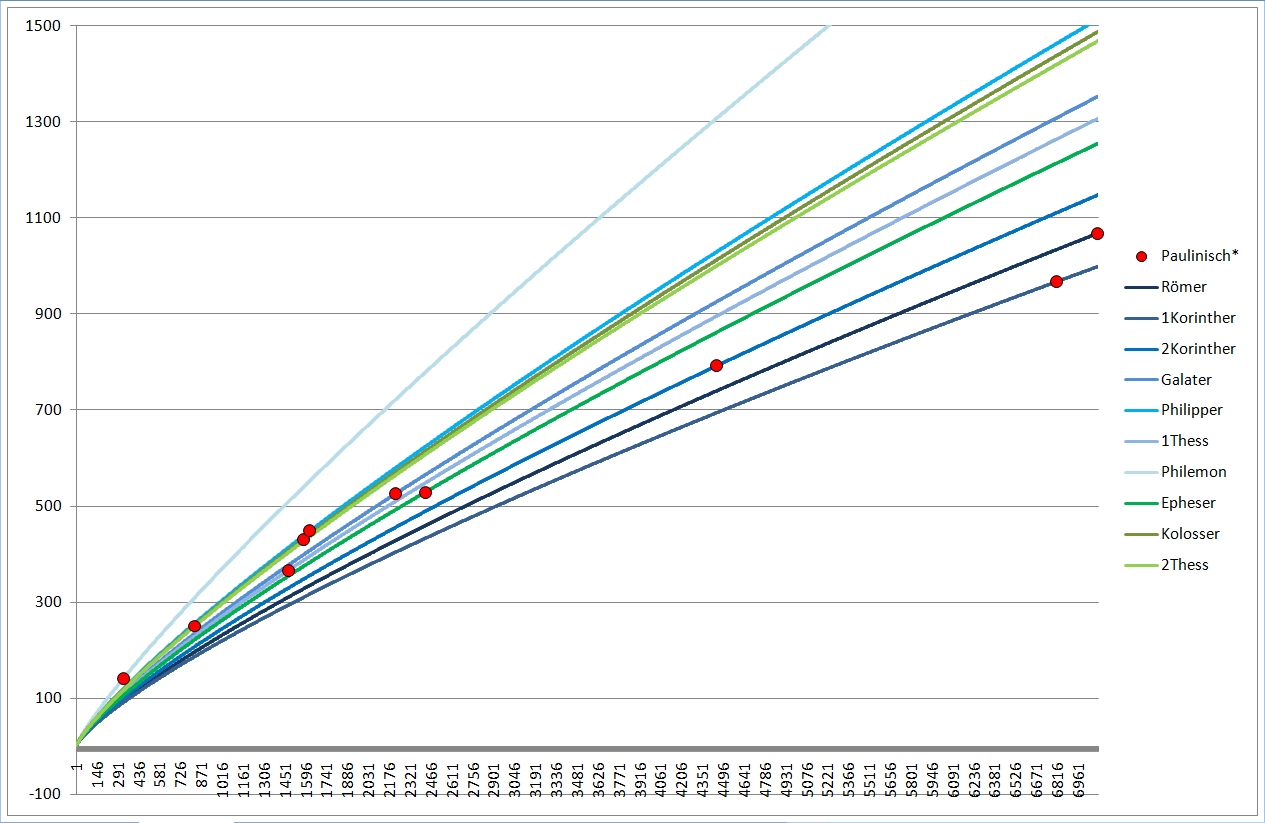
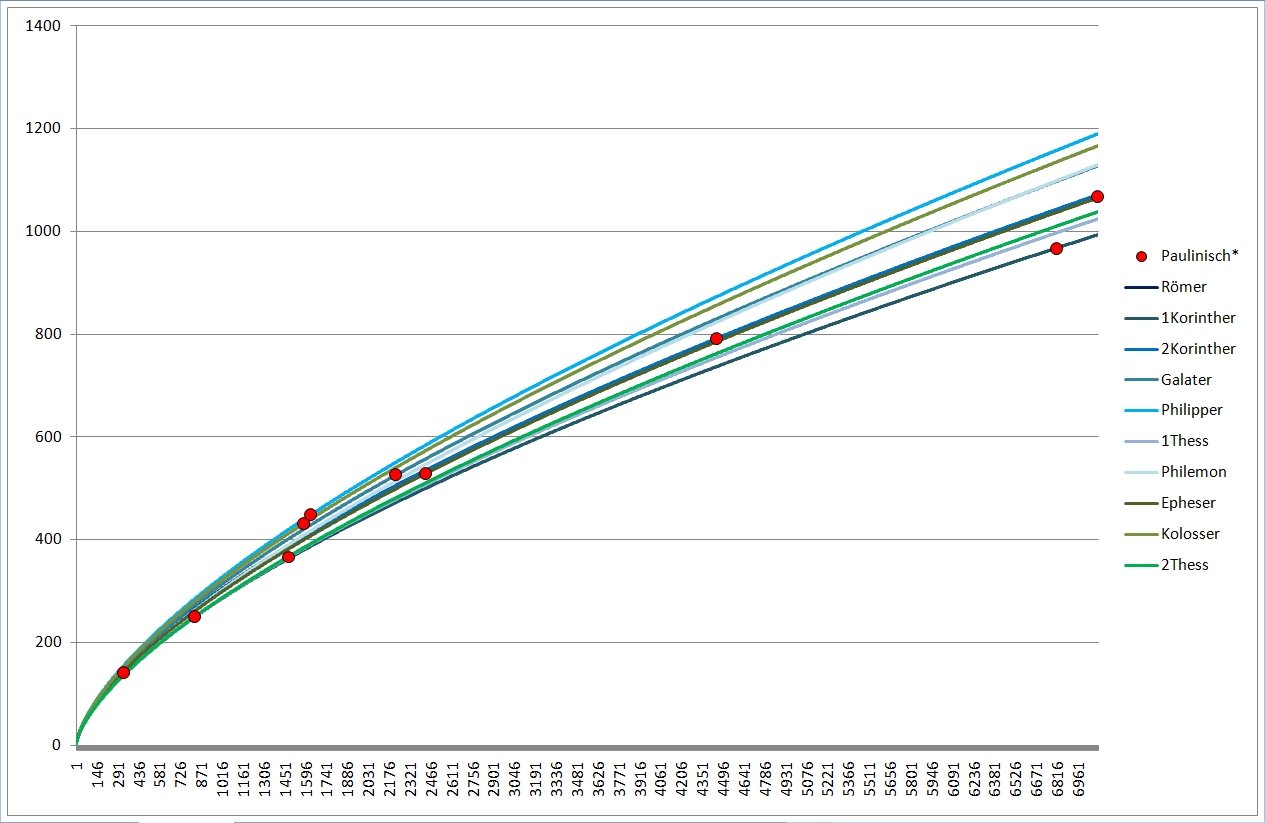
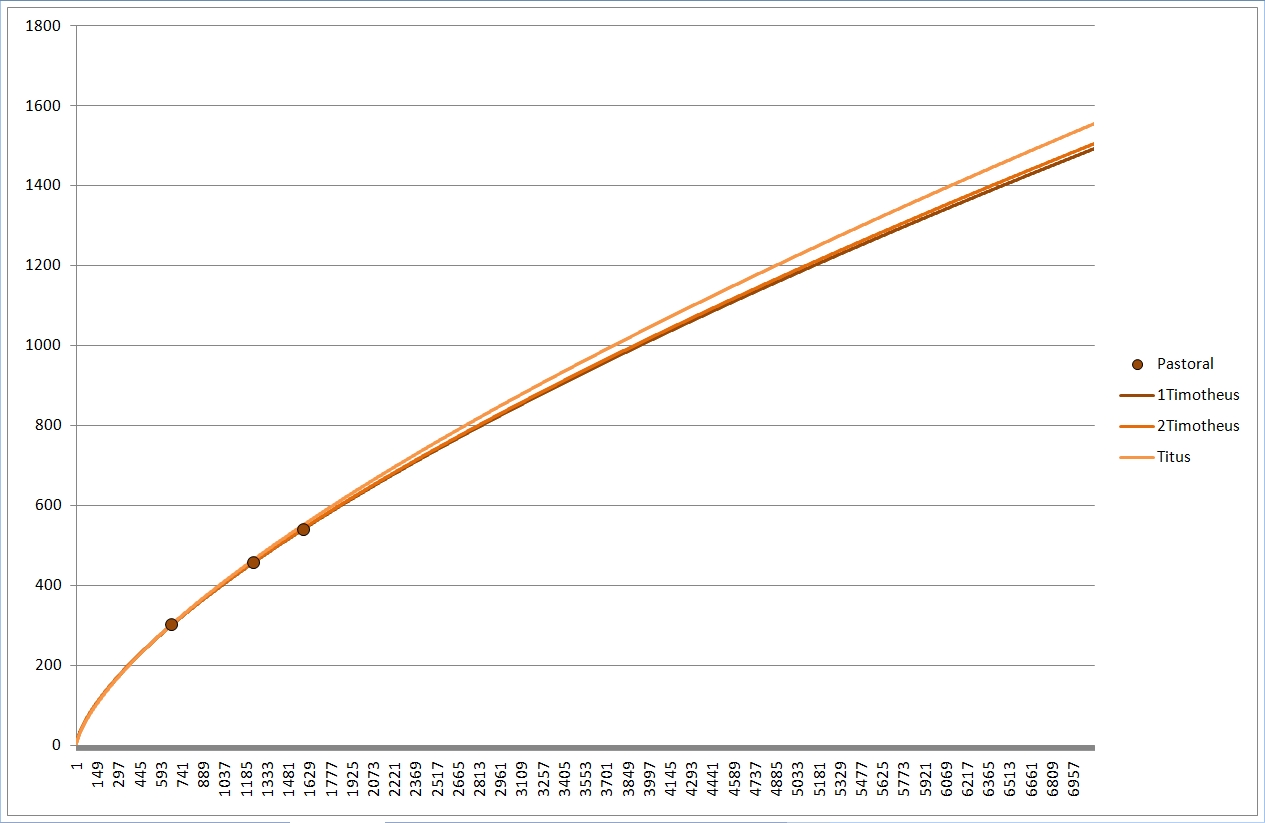
Zum deutlicheren Sehen habe ich mal die Paulusbriefe (rot), die Pastoralbriefe (braun) und die katholischen Briefe (grün) separat wiedergegeben, wobei ich nur noch die Linien des je höchsten und niedrigsten Wortschatzes eingetragen habe. Bei den Pastoralbriefen reichte eine Linie, die liegen geradezu exakt "aufeinander".
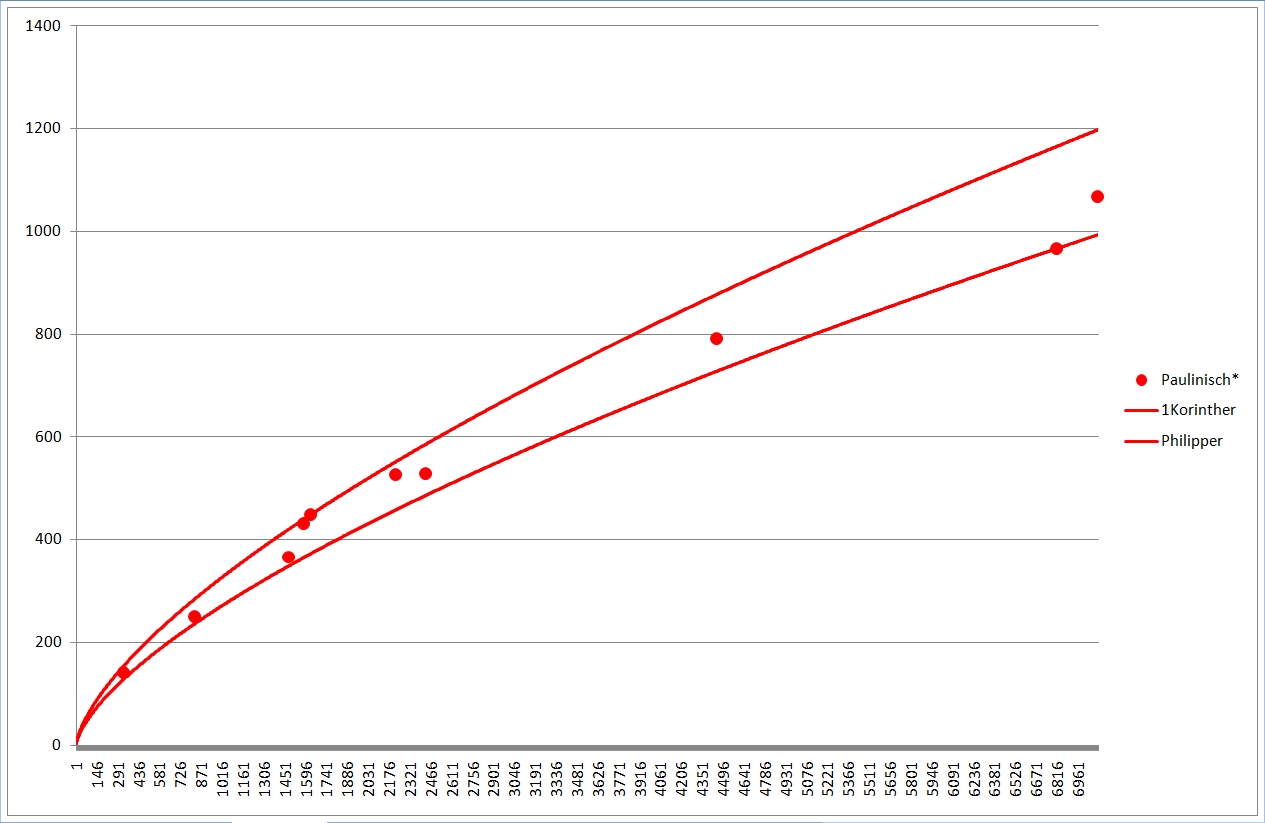
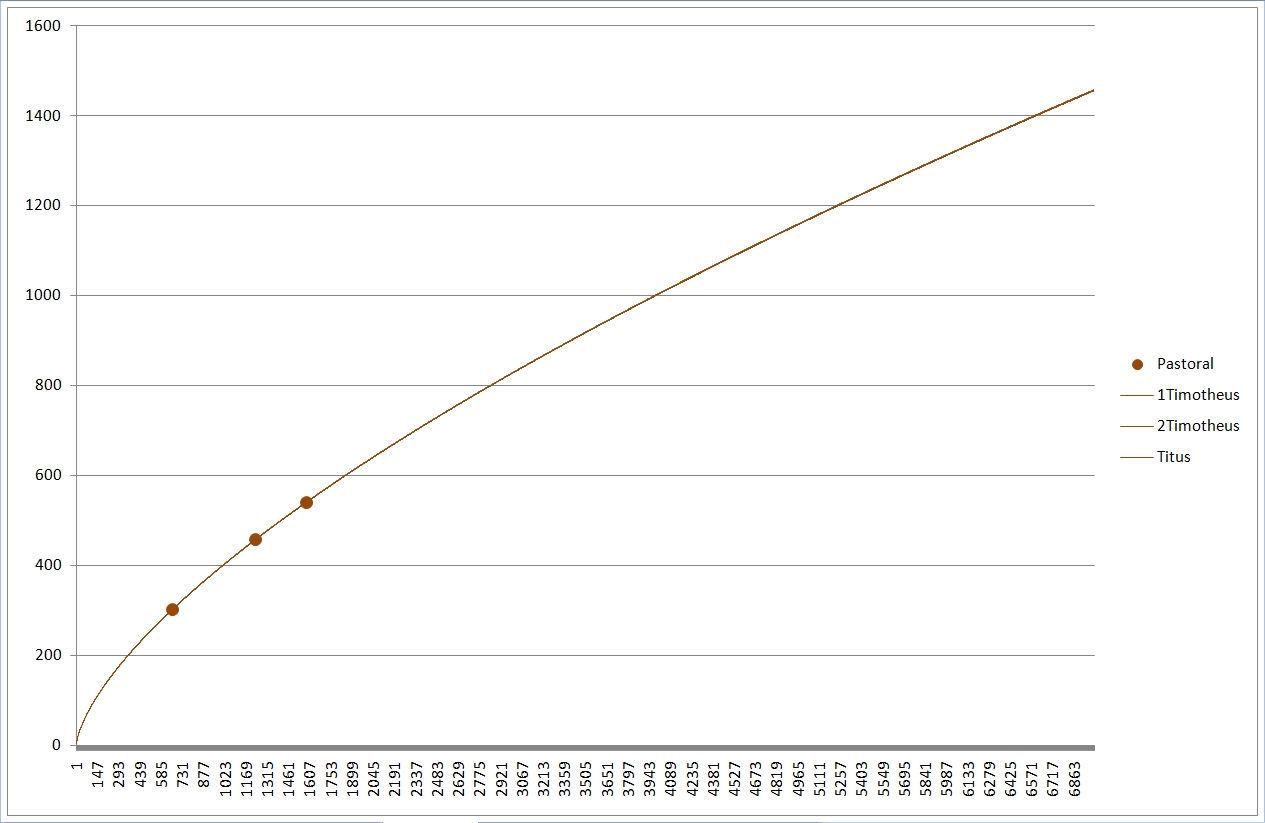
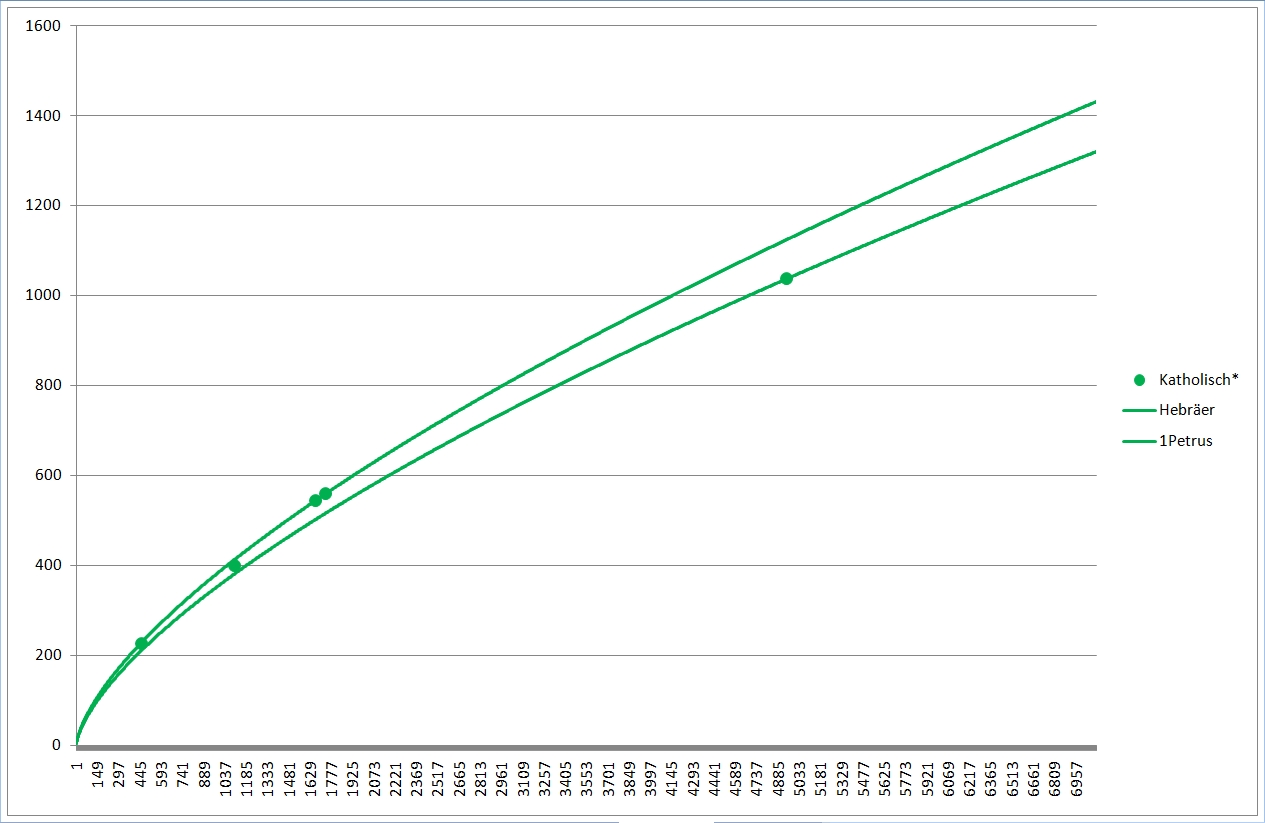
Die Zusammenhänge bzw. Unterschiede der synoptischen (gelb) und johanneischen (blau) Schriften mit ihren extrapolierten Linien sind auch so im Liniengewirr der Gesamtgrafik gut zu erkennen.
Bei Guiraud nun ergibt sich in der Gesamtschau dieses Bild:
Hier liegen die Linien nicht mehr so hübsch nach Farben sortiert beieinander, sondern arg gemischt. Und das widerspricht schon mal der rein visuellen Einschätzung (die Gesamtgrafik ohne Linien am Anfang). Nach Guiraud wäre der Wortschatz zweier Paulusbriefe niedriger als der der Offenbarung des Johannes, einer (roter Punkt ganz links unten) läge sogar bei dem des Johannesevangeliums (rechter blauer Punkt). - Hier ist etwas offenkundig falsch.
Was man hier bereits sehen kann: vor allem lange Texte haben nach Guiraud einen hohen Wortschatz, kurze Texte eher einen niedrigen Wortschatz. Besonders gut zu sehen ist das, wenn ich auch für Guiraud die Paulinen (rot), die Pastoral- (braun) und die katholischen Briefe (grün) je für sich zeige:
Eigentlich sollte die Textlänge keine Rolle spielen, einen wie hohen Wortschatz der Verfasser besitzt. Es sollte gemeinhin eher vermischt sein. Aber deutlich erkennbar ist dies bei Guiraud "sauber sortiert". Und das kann schlicht nicht stimmen.
Bei Herdan nun verhält es sich genau anders herum. Je kürzer ein Text ist, desto höher der Wortschatz. Ich erspare mir einzelne Kommentierungen und stell einfach die Grafiken ein:

Nehme ich hingegen wieder einen der Mittelwerte von Guiraud und Herdan, kommt wieder eine Situation ähnlich wie mit meiner Formel zustande, die der ersten visuellen Einschätzung des Wortschatz-Befundes der Schriften des NT entspricht.
So, da hab ich ziemlich lange dran gesessen, ich mach erst mal Pause.

Noumenon schrieb:Hm... Ich klicke auf deinen Link und sehe...